
認識データの管理
現在のマウンター(実装機)は画像認識が当たり前です。ごくまれにメカチャックをまだ使われているところもありますが、新しく導入する場合は100%画像認識のマウンターになります。

画像認識によるセンタリングはメカチャックによるセンタリングに比べ、部品へのダメージが少なく、精度もよく高速にセンタリングが可能です。
しかし、認識データを適切に管理しないと立ち上げの時間がかかるばかりではなく、装着率などの稼働も不安定になりますし、実装品質的な問題も生じます。画像認識のマウンターが世の中に出てからずいぶん経ちますが、認識データの管理を現場任せで収拾がつかなくなっているところも多いようです。
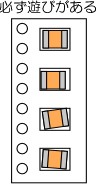
マウンター(実装機)は電子部品をプリント基板の所定の位置に置く機械です。電子部品はフィーダーからノズルで吸着(負圧)し、基板上においていくわけですが、ノズルで吸着するときに、正確に部品の中心を吸着はできません。もちろんなるべく中心に近い位置に電子部品を取りに行きますが、電子部品を納めているリールのポケットやトレーにには必ず遊びがあります。遊びがなければ電子部品がすっぽりはまって抜けないからです。
マウンターはポケットの中心を狙って取りに行くと思ってください。当然遊びの分電子部品は中心からずれます。
昔はこのずれを補正するためにメカチャックという機構を使っていました。メカチャックはX,Y方向に同じ動きをする爪(ジョー)が部品をはさんでノズルの中心に強制的に移動させるものです。
これに対し、画像認識は電子部品の写真を撮り、その画像から寸法を測定しあらかじめ登録された寸法と比較し、範囲内であれば電子部品の中心を計算して割り出し、その分ノズルを移動させて基板上に載せる仕組みになっています。

このあらかじめ登録された部品のデータが、認識データとか、チップデータとか、部品ライブラリと呼ばれるものです。特別な場合を除き、認識データは部品の形状や寸法を登録するものですから、形状の種類だけあれば良いことになります。
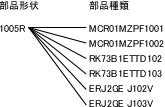
本来なら、部品の形状の数だけ認識データがあれば良いわけですが、実際の現場では同じデータが複数登録されている場面によく出くわします。なぜそうなるのか、どうしたら防げるのか、無秩序に作らてしまった認識データをどう集約させるか、を考えてみたいと思います。
現在では、各マウンターメーカーから使いやすいオフラインのデータ作成ソフトがリリースされていますが、それでもルールを作って管理しないとさまざまな問題が発生する恐れがあります。
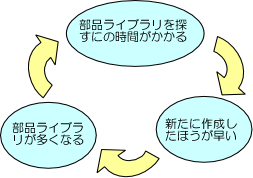
具体的な例を挙げると、旧パナサートをお使いの皆様で、部品ライブラリを作るときに、「確か似たような部品あったな」とか「これ前に作った事があるかも」などと思いながらも、「面倒くさいから新しく作っちゃえ」と無秩序に作ってしまった経験があると思います。
こんな事を繰り返していると、ライブラリがどんどん増えてますます探すのが面倒になってしまい、悪循環を繰り返して困っている人も多いのではないでしょうか。
分かっていながらやってしまうその原因は、部品ライブラリの設定画面は帳票形式となっており、一覧としての視認性に乏しいため、大量のデータを扱うのには向いていないためだと思います。
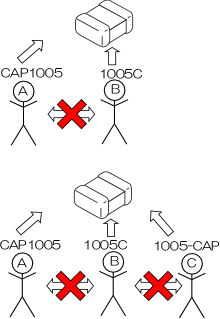
同じ1005のコンデンサをAさんは"CAP1005"という名前で作りました。Bさんは"1005C"という名前で作りました。この時点で、同じ部品寸法で同じ認識データが2つになってしまったわけですからすでに無駄です。本来なら、Aさんが作っ"CAP1005"を使えばいいだけなのにBさんはAさんがどのように認識データを作っているか知らないわけですから、まったく同じ部品でも新しくデータを作ってしまうわけです。さらにここでCさんが登場するともうめちゃくちゃになります。CさんはAさん、Bさんの仕事を知らないわけですからCさんはCさんで、"1005-CAP"などと好きにデータを作ってしまうわけです。ひとつのデータで事足りることを、何度も繰り返す無駄が発生するわけです。
このように、複数人がプログラム作成をしていて、きちんとしたルールがない場合、オペレータやプログラム作成者の俺流ルールで作られてしまいますから、その場では基板を流すことができますが、その情報を次の機種に有効に利用することはできず、新しい基板を立ち上げるときはまた、0からやり直しということになります。
私個人の経験ですが、このような状態を脱するために、まず重複しているデータを絞り込む作業を行いました。部品ライブラリを変換しEXCELで読み込んでフィルターなどを使って、重複しているデータを探し出し一つのデータに統一します。もちろんACCESSで作業しても良いのですが、変換したデータは最後には捨ててしまうので、EXCELでも充分かなと思います。
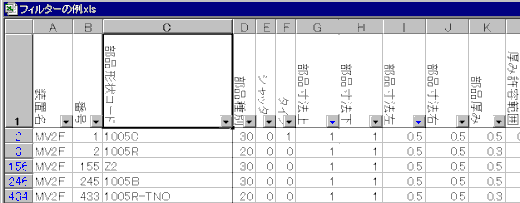
当然消した部品形状コードは、配列から呼ばれていますので、配列も同様に一括データ変換を行い、消された部品形状コードを統一した部品形状コードに置き換えます。
私が作業した結果、部品形状コードの数は440個から293個にまで減りました。実に147個もの無駄なデータを持っていたわけです。
さらに配列プログラムの変換結果から、一度使った部品名称で部品形状コードの検索ができるようになります。PanaPro導入以前の古い設備に関しては大変重宝しました。
EXCELやACCESSの操作に慣れた人なら、ピボットテーブルやクロス集計など使えば、どの部品がどの配列で使われているか、の一覧表も簡単に作成できます。

このように設備のエディターだけでは時間のかかる作業も、PCに変換して取り込んでしまえば様々な形の検索が可能となり、結果的にプログラム作成時間の大幅な短縮が見込めます。
おそらく問題となっているところは、プログラムを作って作りっぱなしで、それを利用する手立て、方法が確立されていないと言うことではないでしょうか。VBA等気軽に利用できる開発ツールで認識データを変換して取り込んでみるのが一番簡単だと思います。これらの開発ツールについては、様々な書籍を参考にしたり、詳しい人に聞いてみるとか、親しい営業に問い合わせてみるといいかもしれません。